Graph‑Based ML Models: Understanding GraphML and Model Architectures
Introduction
Graph‑based machine learning has gained significant importance as data becomes increasingly interconnected in real-world applications. Unlike traditional datasets that assume independent and identically distributed samples, many problems involve relationships between entities. Social networks, molecular structures, transportation systems, knowledge graphs, and recommendation engines are examples of fundamentally relational data. In order to figure out how to extract information efficiently from such well-organised data, the field of research and the engineering community have come up with GraphML approaches, i.e. machine learning techniques that are specially designed for graph data, and also Model Architectures which can understand and take advantage of the interactions.
Why Graph Data Matters
A graph ML is a mathematical model that has nodes (things) and edges (relations) between them. This framework shows how the items are connected in a network, thus allowing the models to use the connections instead of treating the data as independent. So, relationships between friends are important for predicting new friendships in a social network, whereas the atomic bonding pattern tells the properties of a molecule in chemistry.
Therefore, graph-based machine learning is all about utilising the inherent structure and the topology of the graphs to derive improved prediction outcomes.
GraphML is the term used for the machine learning field that works with graph-structured data directly. Usual methods such as linear regression or convolutional neural networks (CNNs) have a hard time getting the relational information because they are based on the assumption that inputs are vectors or grids. GraphML breaks these barriers by feeding relational context to the learning process; thus, the models become capable of representing not only the characteristics of each node but also the way the links affect the results.
Core Model Architectures in GraphML
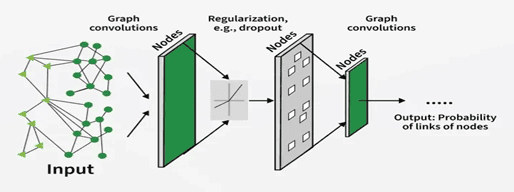
At the heart of GraphML are advanced neural architectures designed for graph data. While various methods exist, the most prominent models fall under the umbrella of Graph Neural Networks (GNNs). These networks generalise deep learning concepts to non‑Euclidean data structures by passing messages along edges and aggregating neighbour information.
One of the foundational Model Architectures is the Graph Convolutional Network (GCN). Inspired by convolutional layers used in image processing, GCNs propagate information across a node’s neighbours to learn meaningful representations. Each layer of a GCN aggregates and transforms neighbour features, effectively letting nodes “learn from their neighbourhood”. As these layers stack, richer global patterns emerge.
Another major architecture is Message Passing Neural Networks (MPNNs). They also extend their capabilities by allowing features of both nodes and edges. In MPNNs, each node gathers messages from its neighbours, changes its representation, and thus the process is repeated over a number of layers. This iterative message‑passing mechanism captures both local and extended graph structure and supports tasks like node classification and link prediction.
Graph Attention Networks (GATs) represent a further evolution of graph architectures. Instead of treating all neighbours equally, GATs use attention mechanisms to weigh neighbour contributions based on importance. This allows the model to prioritise specific relationships that are more informative for the task at hand, improving performance when neighbour relevance varies significantly.
Graph Embeddings and Representation Learning
A common practical approach within GraphML is graph representation learning. This consists of mapping nodes or entire graphs into numerical vectors (embeddings) that capture both feature and relational information. For example, algorithms like node2vec generate low‑dimensional node representations by simulating random walks on the graph and learning from these paths using techniques similar to word embeddings in natural language processing. These embeddings enable downstream tasks such as clustering, classification, or similarity search.
Applications of GraphML Models
GraphML, along with its related Model Architectures, have been adopted extensively across various domains:
Social Networks:
Relationship prediction, community detection, and influence propagation.
Fraud Detection:
Locating the performance of fraud by closely looking at transaction networks.
Biological Sciences:
Predicting molecular properties and drugs–target interactions through molecular graphs.
Knowledge Graphs:
Improving semantic relationships in large datasets for search, QA systems, and reasoning engines.
Since graph structures inherently focus on connections, GraphML models are able to uncover deep relational patterns that flat data models fail to recognise, hence they are more often accurate and provide valuable insights.
Design Considerations in Graph Architectures
Developing effective GraphML Model Architectures involves several choices. Message‑passing depth (number of layers) affects how far information travels in the graph. Too few layers can limit how much relational context a node sees, while too many can lead to “over‑smoothing,” where node embeddings become indistinguishable. Attention mechanisms, as seen in GATs, help address these issues by learning meaningful weights for neighbour contributions.
Another vital consideration is graph size and sparsity. Graphs on a large scale that have millions of nodes need architectures that can scale and computations that are optimised. Also, a combination of neighbour sampling, hierarchical pooling, and sparse matrix operations can be used to control memory and runtime jointly without any noticeable performance loss.
While graph data remains complex, the set of visualisation and explainability tools is getting better and better, thus giving analysts the possibility to grasp the way models arrive at their decisions. Interpretative graph models, for instance, can emphasise the key substructures or the main links that lead to the prediction, which is very helpful for cases involving the transparency factor.
Conclusion
Graph-based machine learning, exemplified by GraphML techniques and advanced Model Architectures, indicates a major change in the way data relationships are modelled and interpreted. Instead of just flat representations, GraphML can handle relational structures that are more expressive and powerful learning systems. The use of graph data and the corresponding models is a potent way to unravel the complexity of interconnected data in any of these domains: social network analysis, biology, recommendation engines, or fraud detection. GraphML is the key to unlocking the full potential of relational data for machine learning.
References
[1] “What are Graph Neural Networks?,” GeeksforGeeks, Nov. 27, 2025. [Online].
Available: https://www.geeksforgeeks.org/deep-learning/what-are-graph-neural-networks/
[2] “GraphML,” Wikipedia. [Online].
Available: https://en.wikipedia.org/wiki/GraphML
[3] “Node2vec,” Wikipedia. [Online].
Available: https://en.wikipedia.org/wiki/Node2vec
[4] “Graph Neural Networks,” TigerGraph Glossary. [Online].
Available: https://www.tigergraph.com/glossary/graph-neural-network-gnn/
Relational ML FAQ
- What is the main focus of this article?
It explores how machine learning treats interconnected data points and the specific structures used to analyze them. - Why is relational data important?
Most real-world information, like friendships or chemical bonds, depends on how entities connect rather than existing in isolation. - What are “nodes” and “edges”?
In a mathematical network, nodes represent individual items (like people), and edges represent the relationships between them (like friendships). - How does this differ from traditional data analysis?
Traditional methods assume data points are independent, while these newer approaches prioritize the links between them. - What is “non-Euclidean” data?
It refers to data that doesn’t fit into a standard grid or list, such as complex web-like structures. - What is a GNN?
It stands for a network designed to process information by passing messages across connections in a dataset. - How do GCNs function?
They allow a single point to “learn” from its immediate neighbors, similar to how image filters look at surrounding pixels. - What makes MPNNs unique?
These systems allow both the entities and the links themselves to hold and share information. - What is the “attention mechanism” in these models?
It allows the system to decide which neighboring connections are more important than others for a specific task. - How does “node2vec” work?
It turns complex positions in a network into simple numerical lists by simulating paths through the data. - What is “over-smoothing”?
This happens when too many layers cause all data points to look exactly the same, losing their unique qualities. - How do layers affect information travel?
The depth determines how far information can move from one side of the network to the other. - How is large-scale data handled?
Techniques like neighbor sampling are used to process millions of points without crashing the system. - Why is sparsity a concern?
When many items have very few connections, the system must be optimized to avoid wasting memory on “empty” space. - Can these decisions be explained?
Yes, new visualization tools help analysts see which specific links led the model to a certain conclusion. - How is this used in biology?
It helps predict how different drugs might interact with specific protein structures. - How does it assist in security?
It identifies suspicious patterns in transaction logs to flag potential financial crimes. - What is a “Knowledge Graph”?
A massive library of interconnected facts used to improve search engine results and AI reasoning. - Can it predict future connections?
Yes, one of its main tasks is determining the likelihood of a new link forming between two points. - Why are these models better than “flat” models?
They see the “big picture” of relationships that simpler models completely ignore.
Penned by Sandhya
Edited by Pranjali, Research Analyst
For any feedback mail us at [email protected]
Streamline Your Hiring with Eve Placement’s Custom Assessments
Eve Placement helps you engage, assess, and recruit top talent through tailored hiring challenges that go beyond resumes. From technical quizzes and real-world case studies to psychometric evaluations and audio/video submissions, our platform enables smarter, data-driven hiring decisions. Advanced security features ensure authenticity and eliminate fraud, giving you reliable results. Ready to hire better? Know More.
Mail us at [email protected]